
Big data là tập hợp dữ liệu khổng lồ và phức tạp, đòi hỏi các công nghệ và phương pháp xử lý đặc biệt. Vậy quá trình xử lý big data diễn ra như thế nào, gồm những bước nào và ứng dụng ra sao?
Big data là gì?
Big data (dữ liệu lớn) là khối lượng dữ liệu khổng lồ, được tạo ra liên tục với tốc độ nhanh và ở nhiều định dạng khác nhau như văn bản, hình ảnh hay video.
Do vượt quá khả năng xử lý của các công cụ truyền thống, big data cần công nghệ và hạ tầng đặc biệt để lưu trữ, phân tích và khai thác. Công nghệ này được ứng dụng rộng rãi nhằm dự đoán xu hướng, hành vi và hỗ trợ ra quyết định hiệu quả hơn.

>>> Xem thêm tại: Ngôn ngữ phổ biến nhất với lập trình viên là gì?
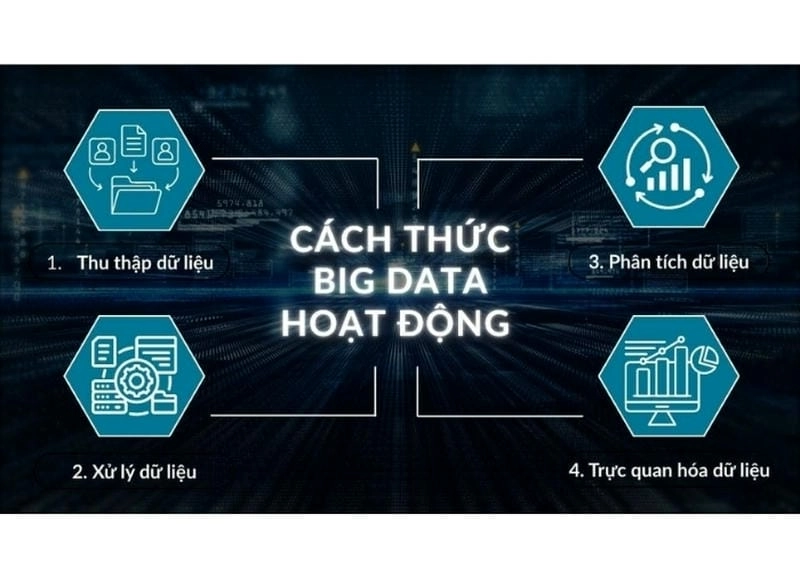
Quy trình xử lý Big data
Để biến Big data thành thông tin có giá trị, chúng ta cần tuân theo một quy trình khoa học, với sự hỗ trợ của các công nghệ tiên tiến.
Thu thập dữ liệu:
Bước đầu tiên là thu thập dữ liệu từ nhiều nguồn khác nhau, chẳng hạn như mạng xã hội, các cảm biến IoT, giao dịch ngân hàng và các trang web.
Lưu trữ dữ liệu:
Kho dữ liệu (Data Warehouse): Đây là nơi lưu trữ dữ liệu có cấu trúc, đã được xử lý.
Hồ dữ liệu (Data Lake): Đây là nơi lưu trữ dữ liệu thô, chưa được xử lý, với nhiều định dạng khác nhau. Các công nghệ máy tính như Hadoop và Apache Spark giúp quản lý các hồ dữ liệu này.
Xử lý dữ liệu:
Sau khi thu thập, dữ liệu sẽ được làm sạch, chuyển đổi và chuẩn hóa để loại bỏ các lỗi và định dạng không nhất quán.
Phân tích dữ liệu:
Đây là bước quan trọng nhất, nơi chúng ta sử dụng các công cụ và thuật toán để tìm ra các mẫu, xu hướng và thông tin ẩn trong dữ liệu.
Các phương pháp phân tích dữ liệu bao gồm:
+ Phân tích mô tả: Diễn tả những gì đã xảy ra trong quá khứ.
+ Phân tích chẩn đoán: Giải thích tại sao một sự việc lại xảy ra.
+ Phân tích dự đoán: Dự đoán những gì sẽ xảy ra trong tương lai.
+ Phân tích đề xuất: Đề xuất các hành động tốt nhất.
>>> Xem thêm tại: Blockchain dùng để làm gì trong đời sống hiện đại?
Những công cụ xử lý Big data
Để xử lý Big data một cách hiệu quả, chúng ta cần sử dụng các công nghệ mạnh mẽ.
Hadoop:
+ Hadoop là một framework mã nguồn mở, cho phép lưu trữ và xử lý dữ liệu khổng lồ trên nhiều máy tính.
+ Nó bao gồm hệ thống tệp tin phân tán (HDFS) để lưu trữ và MapReduce để xử lý dữ liệu song song.
Apache Spark:
Spark là một nền tảng xử lý dữ liệu tốc độ cao, có khả năng xử lý dữ liệu trong bộ nhớ, giúp tăng tốc độ phân tích lên gấp nhiều lần so với Hadoop.
Các công cụ trực quan hóa dữ liệu:
Sau khi phân tích dữ liệu, các kết quả sẽ được trực quan hóa bằng các công cụ như Tableau hay Power BI để dễ dàng hiểu và ra quyết định.
Xử lý big data đòi hỏi sự kết hợp giữa công nghệ, kỹ thuật và chiến lược rõ ràng. Hiểu rõ quy trình này giúp doanh nghiệp khai thác dữ liệu hiệu quả hơn để đưa ra quyết định thông minh.





